溯源明本方知未来|沃丰科技GaussMind带你追溯知识图谱的起源
文章摘要:知识图谱本质上是对图结构模型的研究,包括AAAI、NeurIPS、IJCAI 在内的诸多AI顶级会议都对知识图谱极为重视,在大量学者积极投入与研究后,知识图谱发展进程突飞猛进。




知识图谱本质上是对图结构模型的研究,包括AAAI、NeurIPS、IJCAI 在内的诸多AI顶级会议都对知识图谱极为重视,在大量学者积极投入与研究后,知识图谱发展进程突飞猛进。
关于知识图谱的起源图结构模型,最早我们可以追溯到上个世纪。人们对图结构模型的研究贯穿于现代计算 机技术发展的始末,并与人工智能的发展紧密贴合,共同进退。同时,其内部基础理论离不开语义 Web、数据库、知识表征和推理、自然语言处理、机器学习等领域的研究。
接下来,本文会从知识图谱的起源开始,循序渐进地介绍其诞生的历史,并探讨该学科未来的研究方向。
一、数字时代降临,知识图谱前身语义网络模型初面世(20世纪50-60年代)
在数字计算机出现,第一代编程语言诞生时起,一个崭新的科学研究领域:计算机科学诞生了,它标志着数字时代的伟大降临。
在1956年,国外研究学者Newell、Shaw 和 Simon 开发出了“Logic Theorist”,这是第一个标志性的处理复杂信息的程序。两年后,他们又开发出了“通用解题程序”,该程序是其研究工作的一部分,目的是理解人类智能、适应能力和创造能力背后的信息处理机制,构建可以解决对智能和适应性有所需求的计算机程序,并探索这些程序中有哪些可以与人类处理问题的方式相匹配。同时,这也标榜着自动推理线程的启动。后续理论产出有Robinson 第一定理(归结原理),以及Green 和 Raphael 通过开发问答系统将数据库中的定理证明和演绎联系起来的证明。实践有Oseph Weizenbaum 的 ELIZA 系统。只要程序编写正确,该程序就可以用英语进行关于任何话题的对话。
同期,作为知识图谱前身的“语义网络”诞生了,是在1956年由Richard H.Richens 提出。“语义网络”起初被当作自然语言机器翻译的一个工具,后在1968年由奎林(J. R. Quillian)深化概念,明确了其是用图来表示知识的结构化方式的理念。其底层逻辑为在一个语义网络中,信息被表达为一组结点,结点之间彼此相连带标记的有向直线用于表示它们的关系。
一旦具备了一定的计算能力与自动推理能力后,人们开始可以从非结构化数据,例如文本数据中获取有效信息。其中,具有里程碑意义的项目是Bertram Raphael 于 1964 年发表的SIR: A Computer Program for Semantic Information Retrieval。该系统使用单词关联和属性列表来建模对话语句中传达的关系信息。同时,他们通过格式匹配处理程序从英语句子中提取语义内容。
以上种种研究领域的突破让人们逐步了解到自动推理的重要性和可行性,使用计算机技术理解自然语言的急切需求,语义网络(和更加通用的图表征)作为抽象层的潜力,系统和高级语言对于管理数据的相关性。当然,早期技术上的局限性也凸显了出来,例如硬件的物理、技术和成本限制;图表征和线性之间的差异;人类语言逻辑和计算机系统处理的数据之间的差异等等问题。
二、万维网广泛应用,图形化模型略展锋芒(20世纪80-90年代)
20 世纪 80 年代,随着国外个人电脑的蓬勃发展,计算机技术逐步深入到家家户户。
在数据管理领域,关系型数据库工业发展迅速(Oracle、Sybase、IBM 等公司纷纷入场)。在1989年,Time Berners-Lee发明了万维网,实现了文本间的链接,并在后续几年得到了快速应用。
万维网通过超文本标记语言(HTML)把信息组织成为图文并茂的超文本,利用链接实现在站点之间的跳转,彻底改变了人们交流和交换信息的方式,也摆脱了以前查询工具只能按特定路径一步步地查找信息的限制,打破了时间与空间的限制。
与此同时,学术界继续加深了对图形化模型的研究, 如Harel 于 1988 年提出的图形化编程语言「HiGraph」,开始将图作为面向对象数据、图形化和可视化界面、超文本系统等的表征方式,又如Alberto Mendelzon 他们使用图上的递归式来开发查询语言,这是现代图查询语言的基础。
三、海量数据和知识喷发,知识图谱诞生(21 世纪)
在21世纪,国外电子商务、在线社交网络(例如,Facebook、Twitter)爆炸式增长,从而产生了海量数据。人们第一次面对如此庞大的数据量,但这也让人们对数据的开发与利用产生了全新的认知。人们开始使用新的系统与方法论,如统计方法(通过引入深度学习),
开始在各式各样的落地应用场景中,展现了超越逻辑方法的性能与效率表现。
与此同时,谷歌和亚马逊等互联网公司率先打破常规企业数据管理的思维,跳脱出来,开始构建起互联网数据管理的壁垒,搭建属于自己的互联网帝国,并催生了 NoSQL 数据库,它再一次普及了针对列、文档、键值和图数据模型的数据库管理系统。
海量数据的存在也为人工智能的发展,如统计方法、机器学习、深度学习提供了充实的养料。人们认为统计技术是从已知的事实中推导出新的事实,它使实际应用中的逻辑方法不像以往那样受人关注,产生知识的逻辑方法正在退居幕后。
在这样的背景下,知识图谱的前身语义网络研究领域又产生许多新的研究突破,如Tim Berners-Lee、Jim Hendler 和 Ora Lassila 在「科学美国人」杂志上发表论文「语义网络」。其将数据与知识相结合,基于本文先前介绍的各类技术研究成果之上,尤其是万维网的大量数据、自描述图数据模型(RDF)、描述逻辑和知识工程。
虽然学术界对语义网络的认可度很高,但是在商业上语义网络的落地并不是很完美,可能是对学术界的创新技术的不信任,又或者是一些外部因素,如大公司正在做中心化管理,想要垄断数据市场,对分布式与过于民主的数据管理方式有些排斥等原因。总之最后的结果就是在后续十年中,语义网络并没有像专家预期的那样受到市场与人们的欢迎。
但随着知识处理技术的惊人进步,传统数据管理技术捉襟见肘,局限性凸显出来。这可能就是后续知识图谱概念诞生的主要原因——因为一直缺少一个针对海量数据与知识且集存储、管理和整合功能于一体的模型存在。
时间的滚轴继续向前推进,一路来到2012年,在这年谷歌发布了一款名为Knowledge Graph的产品,即知识图谱。它基于将数据表征为与知识相连的图。从应用的角度可以说,知识图谱是一种多关系图谱(multi-relational graph),图中的结点代表实体(entity)或者概念(concept),边代表实体/概念之间的各种语义关系。从这些特性上,我们可以发现它可以通过不断增加“点”、“边”来进行持续扩充,所以说知识图谱更像是一个不断发展的项目,而不仅仅只是一个精确的概念或系统。
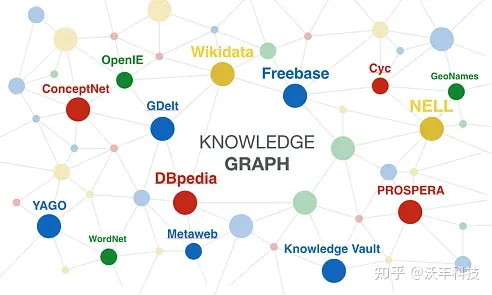
知识图谱就此正式走入人们视野,被市场熟知,并亲睐。同期,相关“图”服务也纷纷涌现出来,如Facebook 发布的图搜索服务、微软、亚马逊、Ebay 等巨头的“知识图谱”类服务。
所谓,溯源明本才能知未来,我们深入了解到那一段发展历程才能站在更高层面去找寻未来知识图谱的发展走向。我们可以看到知识图谱在现如今已弥补了海量数据与知识管理、分析利用的漏洞,当然现在还不完善,有待后续继续补充完整。同时我们大胆展望未来,比如一个知识与数据管理系统,是否可以通过对大量线索的有效整理分析得出既定结论,对事物后续走向实现预测呢?就好像物理学就通过总结、验证大量物理公式,实现了对物体粒子不同时间所处位置、状态的预测。我们有理由相信,基于人类的智慧,早晚有一天会实现对数据与知识使用层面上的升华。
视线移步至今日,我们看到在知识图谱领域发展的企业与组织数量激增。随着人工智能大数据时代来临,知识图谱作为重要的知识表示方式之一,从全新视角为机器语言认知提供支持,使得人工智能对人类自然语言的理解更加精确,从而帮助人类实现更多知识的分析与利用。
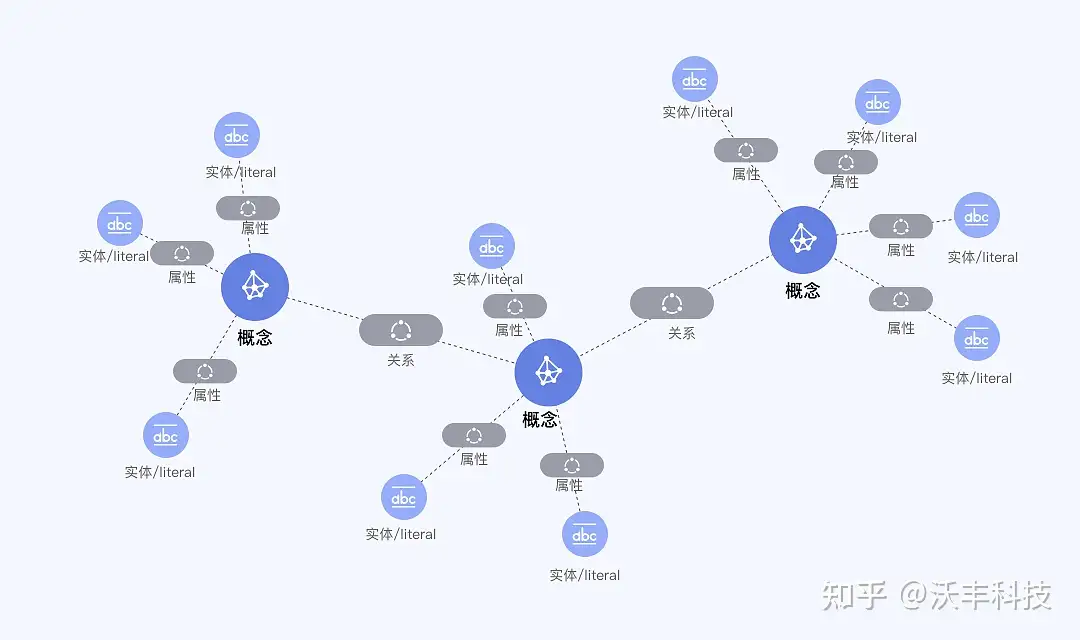
商业发展是除战争外另一大推动技术变革的有力助手,越来越多的企业,投身于知识图谱的商业化发展利用中,沃丰科技也是其中一员。沃丰科技打造了AI场景落地专家GaussMind,其基于深度学习NLP算法,实现上传、标注数据,自定义构建模型训练,构建可视化图谱,将非结构化文档自动构建成知识图谱结构化知识表示GaussMind帮助员工快速查找知识,并构建知识关联,发现未知联系,赋能企业对知识数据的多纬度利用。
未来,沃丰科技将继续深耕于此,以推动中国企业数字化转型为己任,为知识图谱的发展与商业实际场景中的快速落地而持续贡献力量。
》》点击免费试用智能知识图谱,优势一试便知

文章为沃丰科技原创,转载需注明来源:https://www.udesk.cn/ucm/update/27021
